Cengiz Zopluoglu

Deterministic Gated Hierarchical Item Response Model to Simultaneously Identify Compromised Items and Examinees with Item Preknowledge Using Both Response Accuracy and Response Time Data
Ever wondered how to spot test questions that have been compromised or students who got a sneak peek before their exam? In this blog, I walk through a new statistical model that combines both how fast and how accurately people answer test items to flag compromised questions and examinees with prior knowledge—all at once. You’ll find a full walkthrough: model explanation, code, diagnostics, and example results using simulated data. If you’re into psychometrics, cheating detection, or just love seeing R and Stan in action, you’ll get a kick out of this hands-on guide!
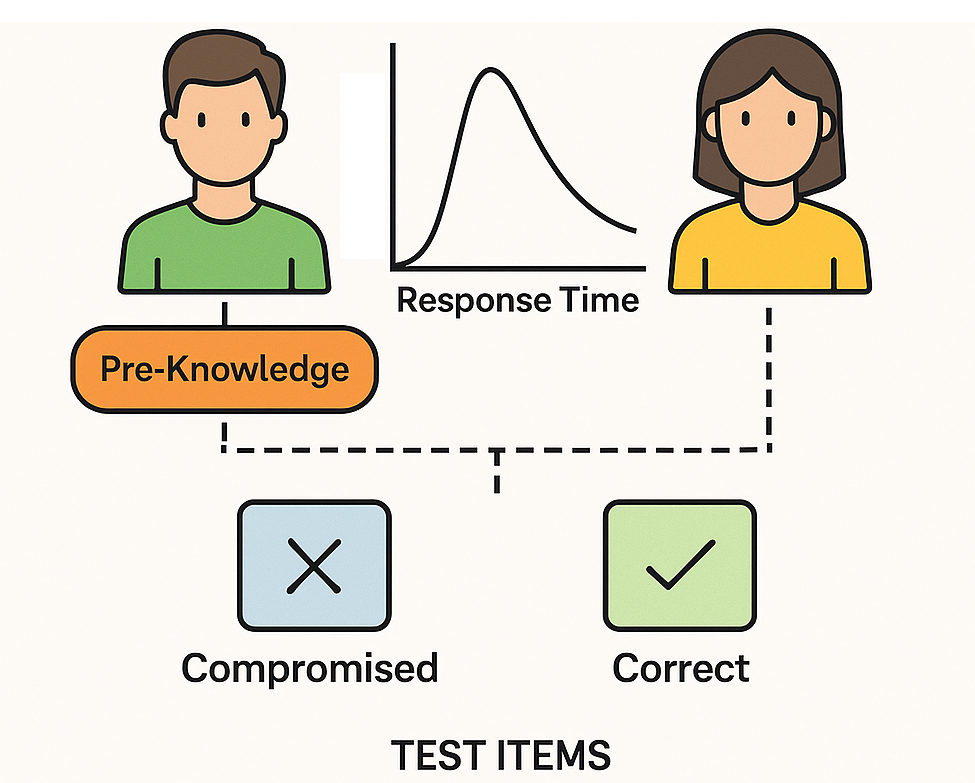
Enhanced Deterministic Gated Lognormal Response Time Model to Simultaneously Identify Compromised Items and Examinees with Item Preknowledge Using Response Time Data
This post introduces the Enhanced Deterministic Gated Lognormal Response Time (DG-LNRT) model—a statistical approach for detecting both compromised test items and examinees with pre-knowledge at the same time using response time data. Unlike traditional methods, this model infers both item and person status as latent variables, jointly estimating them from response time data. The tutorial and open-source code here provide a practical resource for researchers and practitioners aiming to apply this advanced model in test security research.

Enhanced Deterministic Gated Item Response Model to Simultaneously Identify Compromised Items and Examinees with Item Preknowledge Using Response Accuracy Data
This post introduces the Enhanced Deterministic Gated Item Response Model (DG-IRT), a new model developed for detecting both compromised test items and examinees who might have prior knowledge—without needing to know which items are compromised ahead of time. I walk through the model setup, simulation, and a complete Stan implementation, showing how to estimate everything from scratch using only response accuracy data.
Fitting IRT models for zero-and-one inflated bounded continous response data
I’ve published a new tutorial based on a recently published paper with Dr. Lockwood from Duolingo. The tutorial is on fitting IRT models for zero-and-one inflated bounded continous response data. This resource provides a step-by-step guide for performing model estimation and evaluating model fit using Stan. It includes simulated datasets, complete code, and explanations to help users explore advanced IRT modeling techniques discussed in the paper.
NAEP Math Automated Scoring Challenge
In 2023, the National Center for Education Statistics (NCES) hosted the NAEP Math Automated Scoring Challenge to explore the use of automated algorithms for scoring open-ended mathematics responses in large-scale assessments. The challenge aimed to assess whether artificial intelligence could perform scoring tasks as accurately as human raters, while ensuring fairness across diverse student demographics. I was recognized as a runner-up for my submission, which focused on using advanced natural language processing models to handle both symbolic and conceptual information in math problems. I am honored to have participated alongside leading teams from Vanderbilt University and UMass Amherst, contributing to advancements in this important field.
NCME 2022 Presentation
I was not able to go to NCME 2022 this year. Our session organizers, Huijuan Meng and Anjali Weber, kindly let me make an asynchronous video presentation. The session provided a collaborative exercise in which five independent research groups each propose a method that could help effectively and efficiently detect cheaters in the operational setting. Each group used the same data from two linear fixed-form IT certification exams with known security breaches. The five approaches were evaluated regarding their accuracy in detecting cheating and feasibility to implement. Here, I provide the slides, a Github repository for the code, and a video for my presentation.

R, Reticulate, and Hugging Face Models
Join me to get your feet wet with thousands of models available on Hugging Face! Hugging Face is like a CRAN of pre-trained AI/ML models. There are thousands of pre-trained models that can be imported and used within seconds at no charge to achieve tasks like text generation, text classification, translation, speech recognition, image classification, object detection, etc. In this post, I am exploring how to access these pre-trained models without leaving the comfort of RStudio using the `reticulate` package.
Team CrescentStar Won Prizes in the NIJ's Recidivism Forecasting Challenge
Last summer, I participated in the NIJ's Recidivism Forecasting Challenge. Surprisingly, the predictions I submitted won some prizes in certain categories.
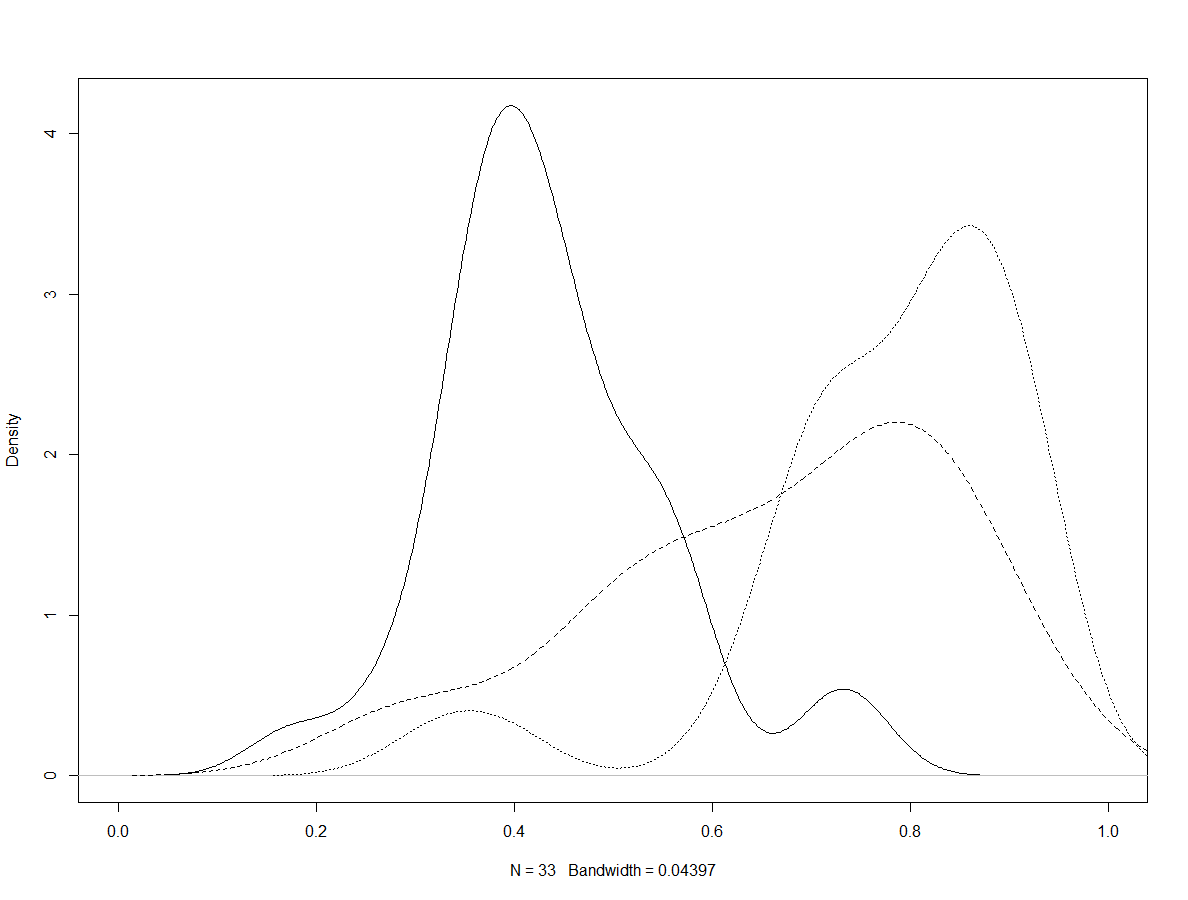
Simultaneous Detection of Compromised Items and Examinees with Item Preknowledge using Response Time Information
Yes, you heard it right! This post introduces a model that uses response time information for simultaneous estimation of items being compromised and examinees having item preknowledge. The model improves upon the ideas laid out in [Kasli et al. (2020)](https://psyarxiv.com/bqa3t), and further relaxes the assumption that the compromised items are known. The model is fitted using a Bayesian framework as implemented in Stan.
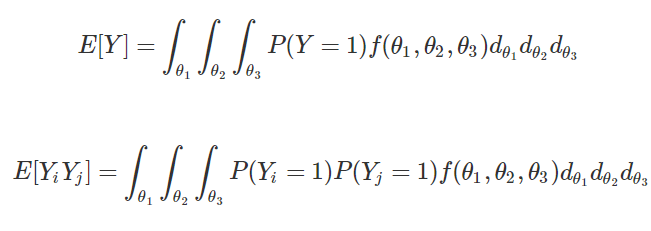
A Fascinating Behind-the-Scenes Look at the Population Covariance Matrix for Multidimensional Items
This post provides R code to use numerical integration for calculating population-level mean and covariances between item scores generated based on the compensatory and partially compensatory multidimensional models.
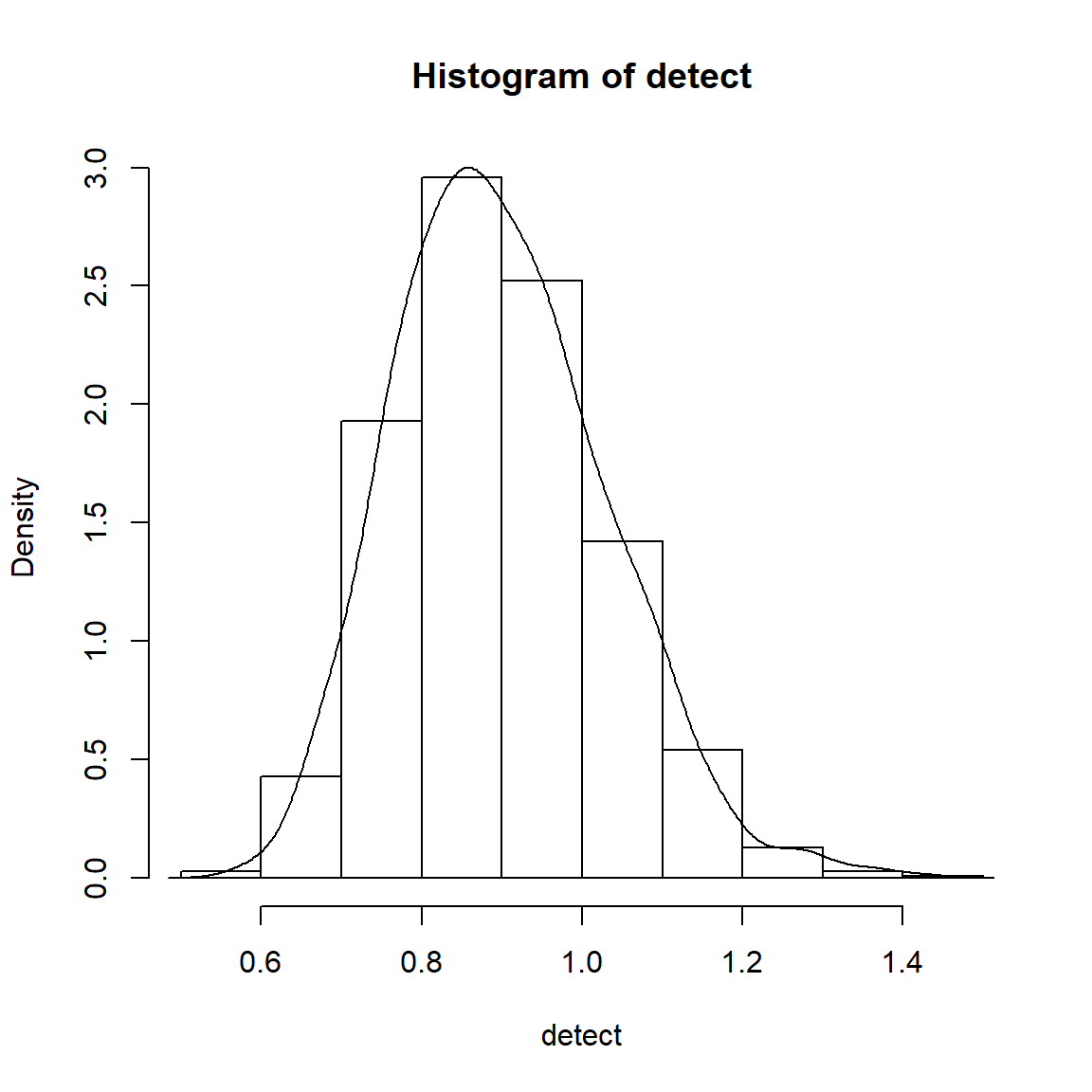
Automated DETECT analysis using R
The post is organized as follows. First, we simulate a dataset using a multidimensional IRT model and compute the actual DETECT value using the correct item partitioning. Second, a brief description of the DETECT index is provided, and the DETECT value is calculated based on this definition based on the true item clustering for the simulated dataset. Then, we compute the same value using the original DETECT program by executing it through R. Finally, we conduct a simple simulation to demonstrate how to automate running DETECT to analyze many datasets and processing the DETECT output files in R.

Equating Oral Reading Fluency Scores from Reading Passages
A non-peer reviewed opinion about how one can equate oral reading fluency scores from two reading passages with different difficulty levels using Samejima's Continuous Response Model.

Tracking the Number of Deceased People by Scraping Data from www.turkiye.gov.tr
A Shiny app is designed to track the number of deceased individuals from 11 major cities in Turkey by scraping data from www.turkiye.gov.tr. By using this Shiny app, you can compare the number of deceased individuals for any given day or date range in 2020 to the number of deceased individuals in the past 10 years on the same day or same date range.

Intersection Points Between Two Adjacent Categories in the Graded Response Model
The interpretation of between-category thresholds in the Graded Response Model is different than the step difficulty parameters in the RSM/PCM/GPCM family due to a different functional form. While the step parameters in the RSM/PCM/GPCM family represent the point on the latent trait continuum where one category becomes more likely than the previous category, it is not the same for between-category thresholds in the Graded Response Model. So, this post is my response to a curious student who wondered at what point on the latent trait continuum the intersections occur between two adjacent categories for the Graded Response Model.

This is a test post with a Shiny App
Shiny app

Measuring Oral Reading Fluency: A Case for Samejima's Continuous Response Model
I pitched the idea of using Samejima's Continuous Response Model (CRM) to measure the Oral Reading Fluency (ORF) a while ago when I published a paper in 2012. In that paper, I used an ORF dataset from the Minneapolis Public Schools District (MPS) as a real data example. Since then, I don't think anybody has bought the idea of using CRM to measure ORF, so here I am trying one more time with some accessible R code.

Fitting Hyperbolic Cosine Model (HCM) For Unfolding Dichotomous Responses using Stan
In this post, I do a quick exercise on fitting the hyperbolic cosine model using Stan. The information about this model can be found in Andrich & Luo (1993). The most interesting part is an "Aha!" moment when I discover the bimodality of posterior distribution due to lack of directional constrain.

2019 Turkish Mayoral Elections – Scraping Ballot Box Level Data
A while ago, I compiled the election data for the 2019 mayoral elections in Turkey, which took place on March 31, 2019, through the Anadolu Agency website, only accessible information back then because the website for the Turkey's Higher Electoral Commission (YSK) was down and they did not make the official election data available until recently. This data was also limited as the Anadolu Agency only provided overall numbers (not for each ballot box). Now, it seems that YSK's website is alive back again and provides a nice-user friendly dashboard for the election data at the ballot box level. However, their dashboard is not very data-analyst friendly for those who has been starving for a more deeper analysis. Here, I provide the data and the R code I used to scrap this data from YSK's website.

XGBoost Analysis of Real Dataset to Predict Item Preknowledge
This post includes supplemental material to reproduce the real data analysis presented in the recently published EPM paper.

Scraping Data for 2019 Local Elections in Turkey
A friend of mine, Dr. Abdullah Aydogan (https://twitter.com/abdaydgn), has asked me this morning if it is possible to pull the data for the 2019 local elections in Turkey. The only accessible information is through the Anadolu Agency (https://www.aa.com.tr/en) because the official election organization's website (http://www.ysk.gov.tr/) has not been working for a while. Here, I provide the code I used to scrap data from the Anadolu Agency, only available source for election results.

Compiling Keywords from the Published Articles in Educational and Pscyhological Measurement
What are the most commonly used keywords in published articles in educational measurement journals? Is there any trending topic in educational measurement journals? I decided to do a sample analysis in the context of Educational and Psychological Measurement (EPM). However, I had figure out first how to compile a dataset of keywords used in EPM. It turned out to be another web scraping story.
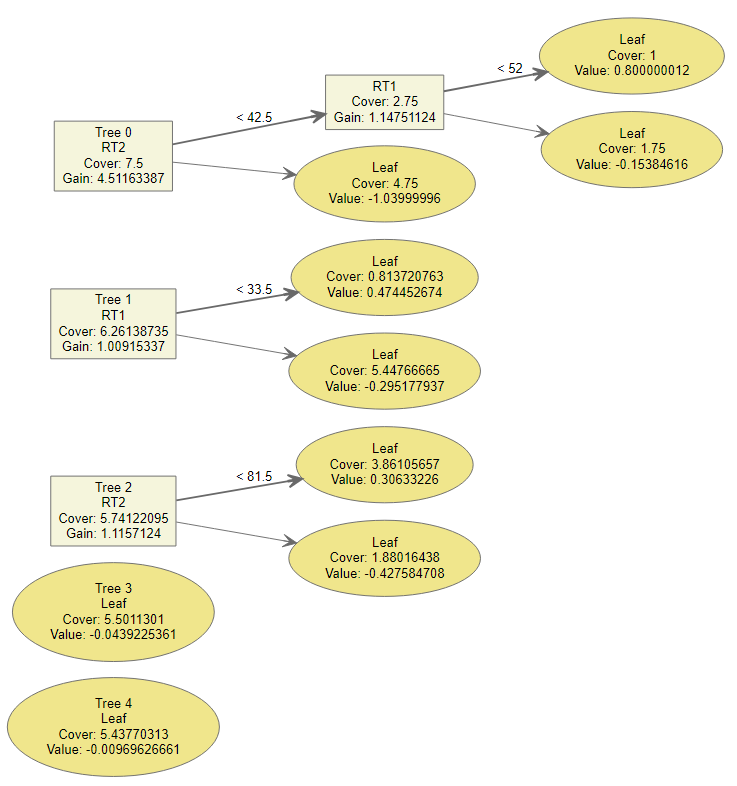
How Does Extreme Gradient Boosting (XGBoost) Work?
In one of the working papers under review, I am using the Extreme Gradient Boosting (XGBoost) to identify examinees with potential item preknowledge in a certification exam. In the original paper, one of the reviewers asked more description of the XGBoost to help readers get a conceptual understanding of how XGBoost works. After spending a few weeks on the original paper, I finally felt that I had a good grasp of it. In this post, I provide an informal introduction of XGboost using an illustration with accompanying R code.

Learning how to create maps in R
Using the elections 2018 data, I practiced how to create a map for an outcome variable,

A Quick Look at the Election 2018
Some quick insights about 2018 elections

